
728x90
1. 범주형 변수
1.1 One-hot encoding(가변수)
- 범주형 변수를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾼 것
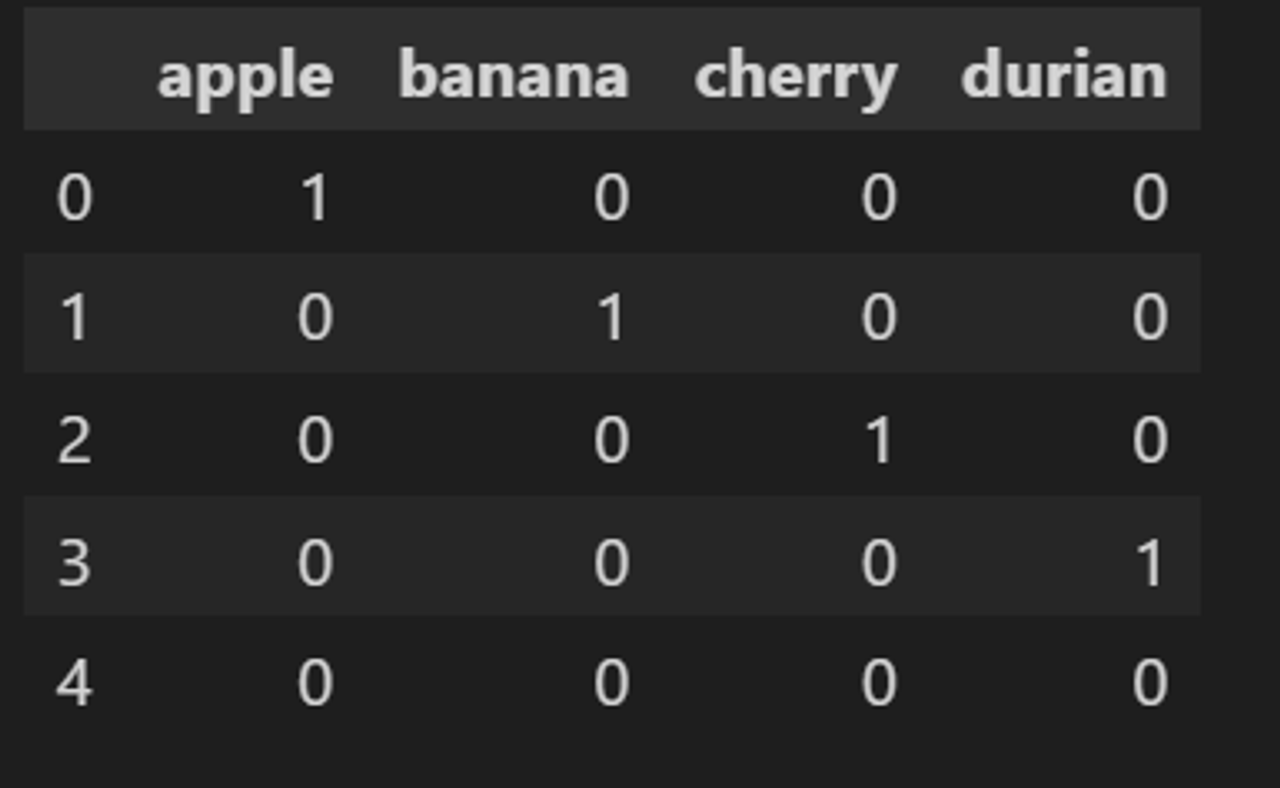
- one-hot-encoding
- one-out-of-N-encoding
- dummy variable
1.2 숫자로 표현된 범주형 특성
- 숫자 특성도 가변수로 만들고 싶다면 columns 매개변수에 인코딩하고 싶은 열을 명시해야 함
2. 구간 분할, 이산화, 그리고 선형 모델, 트리 모델
- 선형 모델: 선형 관계로만 모델링하므로 특성이 하나일 땐 직선으로 나타남
- 연속형 데이터에 강력한 선형 모델을 만드는 방법: 구간 분할(bining)
3. 상호작용과 다항식
- 특별히 특성을 풍부하게 나타내는 방법: 원본 데이터에 상호작용(interaction)과 다항식(polynomial)을 추가하는 것
- 특성을 추가하지 않아도 성능이 비슷할 수 있음(ex. 랜덤 포레스트)
- 특성을 추가하면 성능을 높일 수 있음(ex.선형모델)
- 다항식 특성을 선형 모델과 함께 사용 $\rightarrow$ *다항회귀(polynomial regression)*모델
4. 일변량 비선형 변환
- 트리 기반 모델은 특성의 순서에만 영향을 받음, 선형모델과 신경망은 각 특성의 스케일과 분포에 밀접한 연관이 있음
- 정수 카운트: ex. 사용자가 얼마나 자주 로그인하는가?
- 구간분할, 다항식, 상호작용은 데이터가 주어진 상황에서 모델의 성능에 큰 영향을 줄수도 있음
- 선형모델, 나이브 베이즈 모델(덜 복잡한 모델)
- 트리 기반 모델은 스스로 중요한 상호작용을 찾아낼 수 있고 대부분의 경우 데이터를 명시적으로 변환하지 않아도 됨.
- SVM, 최근접 이웃, 신경망
- 선형 모델 만큼 구간 분할, 상호작용, 다항식의 영향이 뚜렷하지 않음
5. 특성 자동 선택
어떤 특성이 좋은걸까? : 일변량 통계(univariate statistic), 모델 기반 선택(model-based selection), 반복적 선택(iterative selection) -> 모두 지도 학습 방법: 최적값을 찾기 위한 타깃값 이 필요
5.1 일변량 통계: 개개의 특성과 타깃 사이에 중요한 통계적 관계가 있는지 계산
- 일변량: 각 특성이 독립적으로 평가된다는 점
- 모델 사용하지 않음
5.2 모델 기반 특성 선택
- 지도 학습 머신러닝 모델을 사용하여 특성의 중요도를 평가해서 가장 중요한 특성들만 선택
- 하나의 모델을 사용함
5.3 반복적 특성 선택
- 특성의 수가 각기 다른 일련의 모델이 만들어짐
- 방법1: 특성을 하나도 선택하지 않은 상태로 시작해서 어떤 종료 조건에 도달할 때까지 하나씩 추가하는 방법
- 방법2: 모든 특성을 가지고 시작해서 어떤 종료 조건이 될 때까지 특성을 하나씩 제거해가는 방법
요약
- 여러 종류의 데이터 타입을 다루는법
- 새로운 특성을 만드는 것, 데이터에서 특성을 유도하기 위해 전문가의 지식 활용
- 선형모델: 구간 분할, 다항식, 상호작용 특성을 추가해 큰 이득
- 랜덤 포레스트, SVM과 같은 비선형 모델은 특성을 늘리지 않고 복잡한 문제 학습 가능
Reference
- 핸즈온 머신러닝 책
728x90
반응형
'Study > 머신러닝' 카테고리의 다른 글
| [ML] 모델 평가와 성능 향상 (0) | 2024.04.04 |
|---|---|
| [ML] 비지도 학습과 데이터 전처리 (0) | 2024.04.03 |
| [ML] 지도학습(Supervised Learning) 요약 정리 (0) | 2024.04.03 |
| [ML] Machine Learning 스터디 개요 (1) | 2024.04.03 |