
https://arxiv.org/abs/2308.06721
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves
arxiv.org
1. Introduction
Text prompt를 사용한 이미지 생성은 좋은 성능을 보였지만, text만으로 원하는 이미지를 만드는 것은 한계가 있었다. image prompt는 text prompt보다 더 많은 정보와 디테일을 담을 수 있기 때문에 image prompt가 많이 사용되었다. 본 논문은 이러한 아이디어에 따라 간단한 방식으로 Text-to-Image Diffusion model에 image prompt를 통해 생성 기능을 강화하고자 한다.
SD Image Variations 와 Stable unCLIP과 같은 이전 연구는 이미지 임베딩에서 직접 text-conditioned diffusion model을 fine-tuning하여 그 효과를 증명하였음. 그러나 이러한 방법의 단점은 다음과 같음.
- Text 를 사용하여 이미지를 생성하는 기존 기능을 제거하고, fine-tuning을 위해 큰 컴퓨팅 리소스가 필요하다.
- 이미지 prompt 기능을 동일한 Text to Image 모델에서 고안된 다른 custom 모델로 전송할 수 없기 때문에 fine-tuning된 모델은 재사용이 불가능하다.
- 새로운 모델은 ControlNet과 같은 기존 구조 제어 툴과 호환되지 않는 경우가 많아 downstream application에 문제를 야기한다.
이러한 문제에 따라 Prompt-free diffusion과 같은 모델은 텍스트 인코더를 이미지 인코더로 대체하는 것을 선택했는데 이 또한 단점이 있다.
- Image prompt만 지원되기 때문에 사용자는 Text, Image prompt를 동시에 사용할 수 없음
- Image encoder를 fine-tuning하는 것만으로 이미지 품질이 보장되지 않고, 일반화 문제가 발생할 수 있음
저자들은 기존 Text-to-Image 모델을 수정하지 않고 Image prompt를 사용할 수 있는지 궁금했다. ControlNet과 T2I-Adapter는 기존 text-to-image diffusion model에 추가 네트워크를 연결하여 이미지 생성을 가이드할 수 있음을 증명하였다(대부분의 논문이 추가 네트워크를 사용하였음). 이를 위해서 CLIP image encoder에서 추출된 image feature는 학습 가능한 Adapter를 사용하여 맵핑된 다음 text feature와 concat되고(기존 Text feature → Text feature + Adapter를 거친 image feature), 이 feature가 diffusion model의 Unet에 들어간다.
저자들은 이런 cross-attention module때문에 앞서 나온 문제들이 나온다고 주장한다. pre-trained diffusion model에서 cross-attention layer의 key와 value projection의 가중치는 text feature에 맞게 학습되기 때문에 image & text feature를 cross-attention layer에 병합하면 image feature를 text feature에 정렬하는 것에 불과하기 때문에 이미지의 세부적인 정보를 놓친다고 한다.
저자들은 이를 해결하기 위해 IP-Adapter라는 image prompt adapter를 제안하였다.
- Key word: Decoupled cross-attention mechanism
2. Related Work
최근 Text-to-Image Diffusion model은 기존 모델에 Adapter를 적용한 모델에 대한 이야기
3. Method
3.1. Prelimiaries
- 기본적인 Diffusion model의 이야기
- DDPM
- Training objective of diffusion model
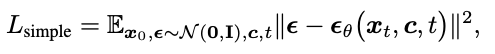
- fast samplers
- DDIM
- PNDM
- DPM-solver
- conditional diffusion model
- classifier guidance(Diffusion model beat gans on image synthesis)
- classifier-free guidance
3.2. Image Prompt Adapter
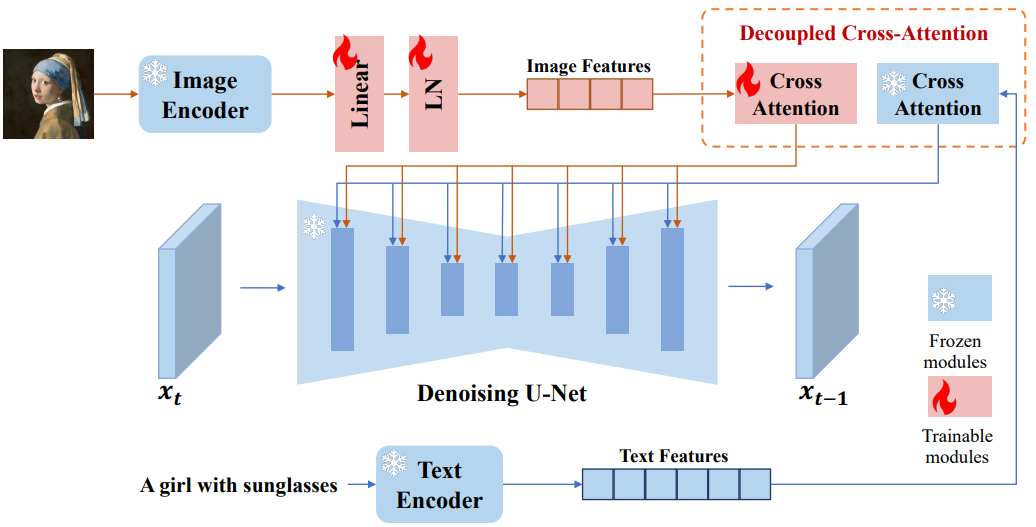
Image Adapter는 pretrained text-to-image diffusion model을 사용해 image prompt가 포함된 이미지를 생성할 수 있도록 만들어졌다. 기존 대부분 방법론의 concat된 feature를 고정된 cross-attention layer에 공급해 diffusion model이 image prompt로부터 세밀한 특징을 포착하는 것을 방해한다. 이 문제를 해결하기 위해 저자들은 위 그림과 같이 image feature가 임베됭 되는 cross-attention layer를 추가하였다. IP-Adapter는 두 가지로 구성된다.
더보기
- image prompt로부터 image feature를 추출하는 image encoder
- image feature를 pretrained text-to-image diffusion model에 임베딩하기 위한 decoupled cross-attention 모듈
3.2.1. Image Encoder
대부분 방법론과 마찬가지로 pretrained CLIP image encoder 모델을 사용해서 image prompt에서 image feature를 추출했다. 학습 과정에서는 CLIP image encoder는 고정(freeze)하였음.
global image embedding을 효과적으로 분해하기 위해 linear layer와 Layer Normalization으로 구성된 trainable projection network를 사용해 이미지 임베딩을 길이 $N$(본 논문에서 $N=4$)의 feature 시퀀스로 porject한다. 이 때 이미지 feature의 차원은 pretrained diffusion model의 text feature와 동일하다.
3.2.2. Decoupled Cross-Attention
image feature는 decoupled cross-attention을 갖는 adapted module에 의해 pretrained Unet에 통합된다. 원본 Stable Diffusion 모델에서 CLIP text encoder의 text feature는 cross-attention layer에 공급되어 UNet에 연결된다. Query feature $Z$와 text feature $c_t$가 주어지면 cross-attention의 output $Z^\prime$은 아래와 같이 정의할 수 있다.
$$Z^\prime = \textrm{Attention} (Q, K, V) = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) V \\
\textrm{where} \; Q = ZW_q, \; K = c_t W_k, \; V = c_t W_v$$
저자들은 text feature와 image feature를 위한 cross attention layer가 분리된 decoupled cross-attention mechanism을 제안했다. cross-attention layer를 기존 UNet 모델의 cross-attention layer에 cross-attention layer를 추가하여 이미지 feature를 삽입한다. 이미지 feature $c_i$가 주어지면 새로운 cross-attention의 output은 $Z^{\prime \prime}$은 아래와 같이 계산된다.
$$Z^{\prime \prime} = \textrm{Attention} (Q, K^\prime, V^\prime) = \textrm{Softmax} (\frac{Q(K^\prime)^\top}{\sqrt{d}}) V^\prime \\
\textrm{where} \; Q = ZW_q, K^\prime = c_i W_k^\prime, V^\prime = c_i W_v^\prime$$
text cross-attention과 image cross-attention에 대해 동일한 query를 사용했다. 결과적으로 각 cross-attention layer에 두 개 파라미터 $W^\prime_k , W^\prime_v$만 추가하면 된다. 수렴 속도를 높이기 위해 $W^\prime_k , W^\prime_v$는 $W^_k , W_v$에서 초기화하였다. 그 다음, image cross-attention을 text cross-attention output에 더하였다. 최종적인 decoupled cross-attention의 공식은 아래와 같고, 기존 UNet을 얼려놓았기 때문에 $W^\prime_k , W^\prime_v$ 만 학습하면 된다.
$$Z^\textrm{new} = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) V + \textrm{Softmax} (\frac{Q(K^\prime)^\top}{\sqrt{d}}) V^\prime$$
3.2.3. Training and Inference
학습 과정에서는 pretrained diffusion model의 파라미터를 고정하고 IP-Adapter만 최적화하였고, 원본 Stable Diffusion과 동일한 목적 함수를 사용하여 image-text pair 데이터셋에 학습되었다.
$$L_\textrm{simple} = \mathbb{E}_{x_0, \epsilon, c_t, c_i, t} \| \epsilon - \epsilon_\theta (x_t, c_t, c_i, t) \|^2$$
inference 과정에서는 classifier-free guidance를 활성화하기 위해 학습 단계에서 image condition을 랜덤으로 삭제하였다.
$$\hat{\epsilon}_\theta (x_t, c_t, c_i, t) = w \epsilon_\theta (x_t, c_t, c_i, t) + (1-w) \epsilon_\theta (x_t, t)$$
image condition이 제거되면 CLIP 이미지 임베딩을 0으로 설정하였다. text cross-attention과 image cross-attention이 따로 분리되어있기 때문에 inference 과정에 image condition의 가중치를 조절할 수 있다. $\lambda = 0$이면 기존 text-to-image diffusion model이 된다.
$$Z^\textrm{new} = \textrm{Attention} (Q, K, V) + \lambda \cdot \textrm{Attention} (Q, K^\prime, V^\prime)$$
4. Experiments
4.1. Implementation Details
- Trianing
- LAION-2B, COYO-700 데이터셋
- SD v1.5
- OpenCLIP ViT-H/14 image encoder
- SD의 16개의 cross-attention layer에 새로운 image cross-attention layer를 추가
- 빠른 학습을 위한 DeepSpeed ZeRo-2 사용
- 8 V100 GPUs for 1M steps with batch size of 8 per GPU
- 512 x 512 resoultion으로 resize
- classifier-free guidance, image나 text 조건을 각각 제거하거나 둘 다 제거하기 위한 확률로 0.05를 사용
- Inference
- DDIM sampler with 50 steps
- guidance scale: 7.5
- only image prompt → $\lambda = 1.0$
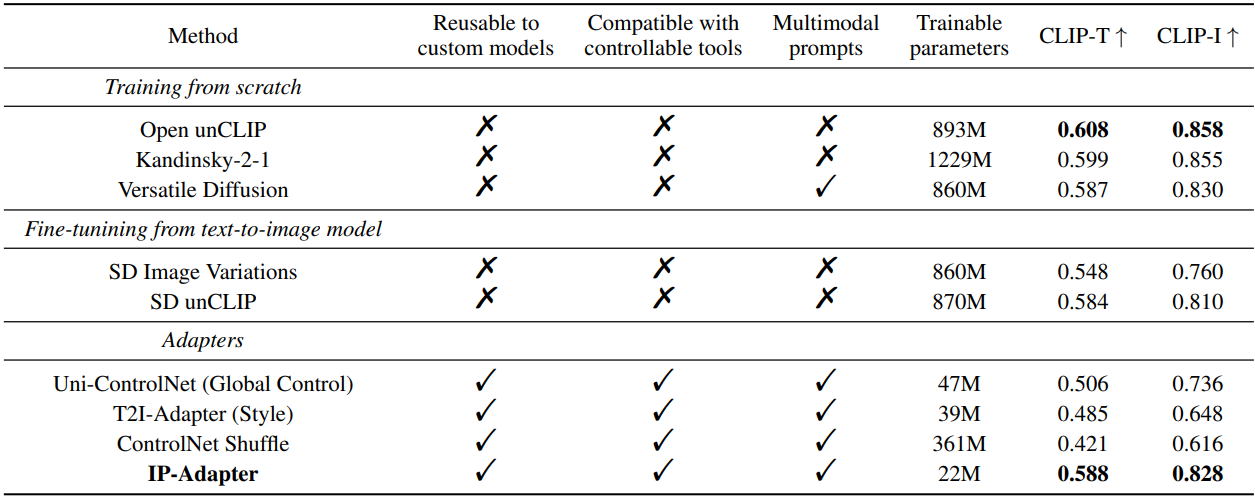
4.2. Comparison with Existing Methods
3가지 타입의 방법론을 비교하였다.
- Training from scratch
- Fine-tuning from text-to-image model
- Adapters
COCO validation set에 따른 비교
- 각각 4개의 이미지를 생성
- CLIP-I: image prompt와 CLIP image embedding의 유사도
- CLIP-T: image prompt의 캡션과 생성된 이미지의 CLIP score
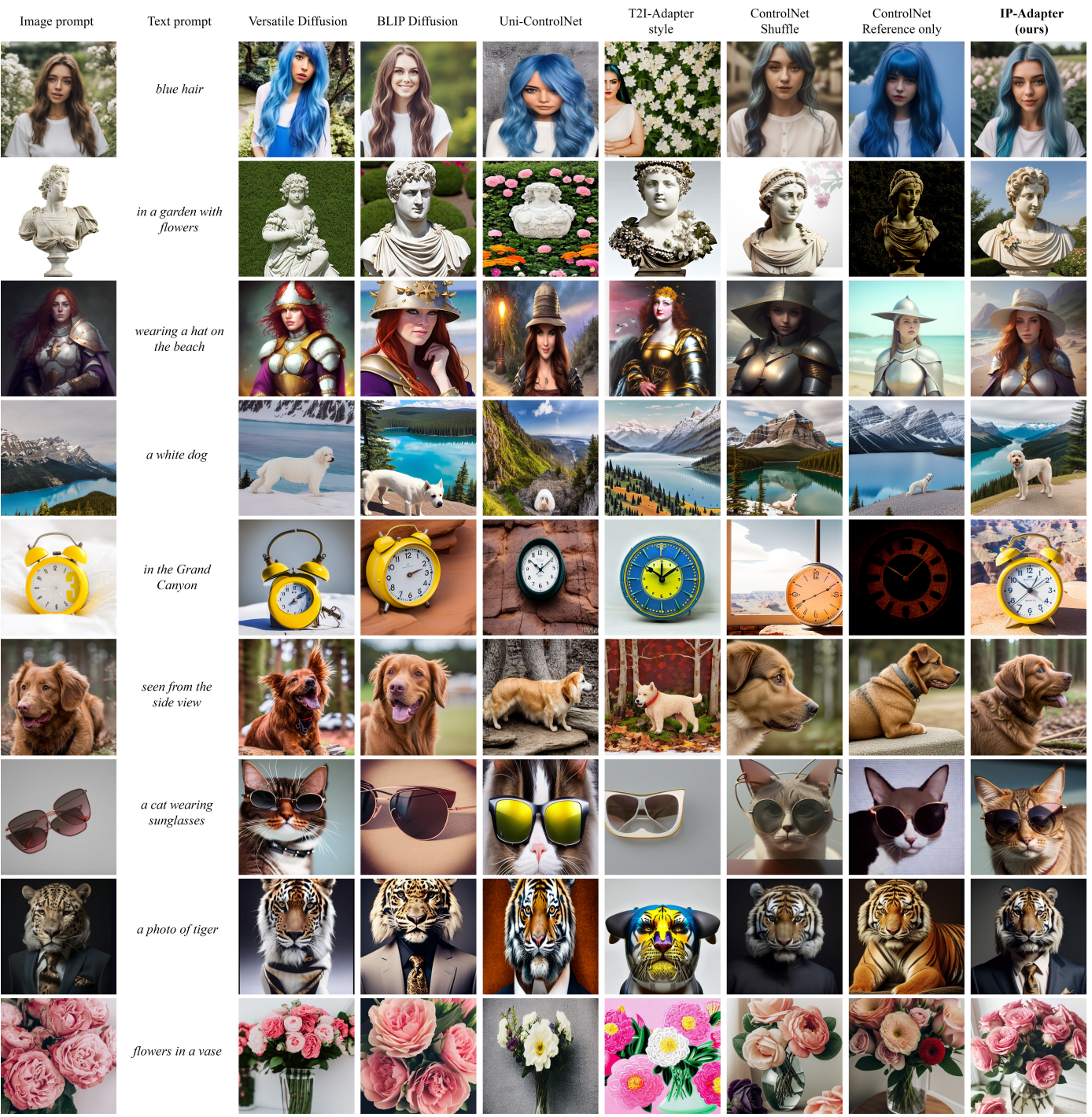
다른 종류와 스타일에 따른 이미지 결과 비교

image prompt와 추가 structual condition에 따른 결과

다른 structural condition에 따른 결과 비교
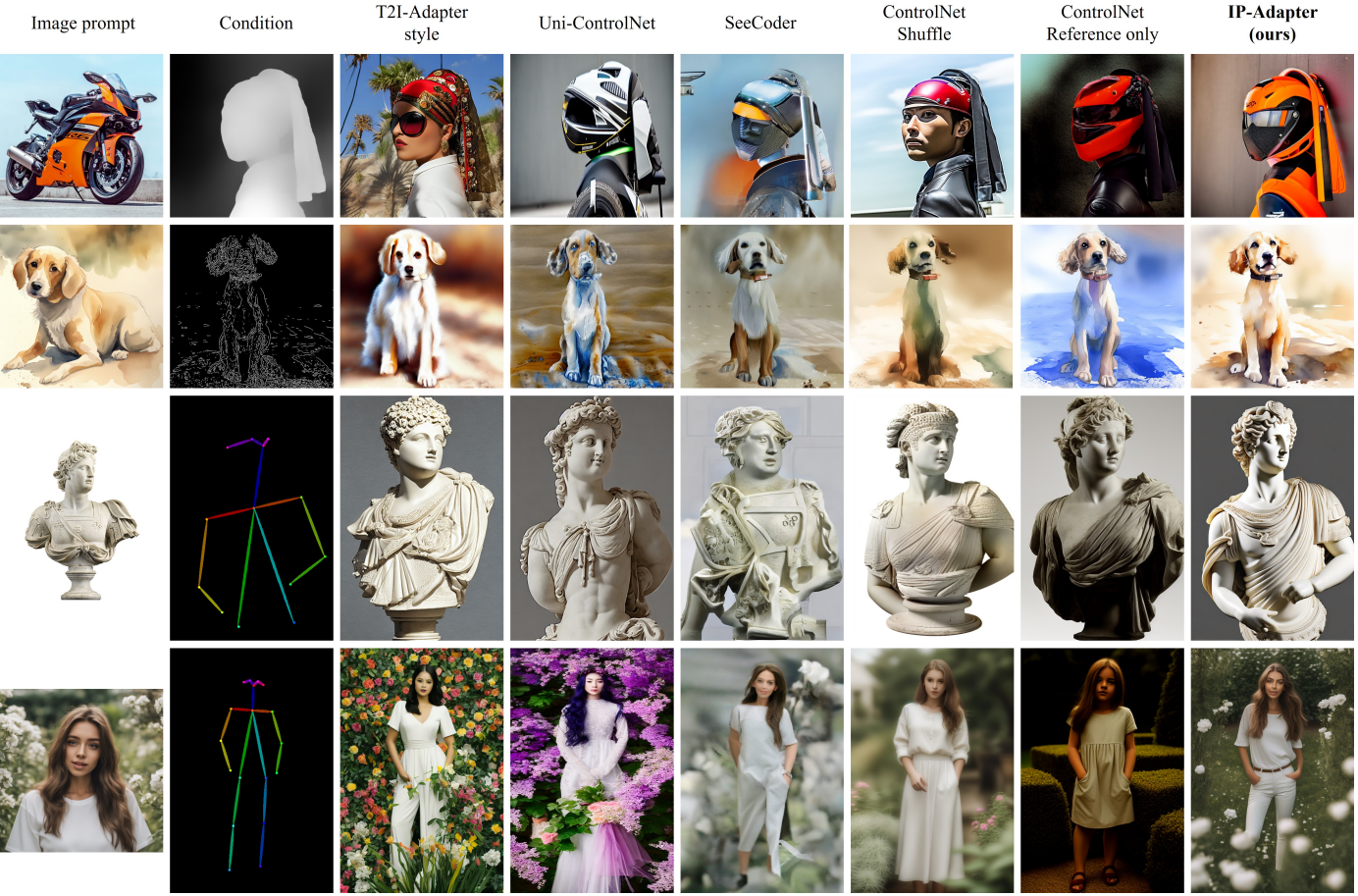
Image-to-Image & Inpainting 결과

Multimodal prompt에 따른 결과 비교
5. Conclusion
IP-Adapter를 제안하여 image prompt를 pretrained text-to-image diffusion model에 성공적으로 적용시켰다.
Image prompt를 pretrained T2I Diffusion model에 성공적으로 적용시킴. Decoupled cross-attention layer라는 방법을 사용했는데 $Z^\prime$이 더하는게 아닌 다른 방법은 어떤게 있을까...
'Study > Paper' 카테고리의 다른 글
| [논문리뷰] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (0) | 2024.05.16 |
|---|---|
| [논문 리뷰] Generative Adversarial Networks (0) | 2024.04.03 |
| [논문리뷰] NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis (0) | 2023.06.06 |
| [논문리뷰] SinDiffusion: Learning a Diffusion Model from a Single Natural Image (0) | 2023.06.06 |
| Diffusion summary1 (0) | 2023.05.16 |
https://arxiv.org/abs/2308.06721
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Recent years have witnessed the strong power of large text-to-image diffusion models for the impressive generative capability to create high-fidelity images. However, it is very tricky to generate desired images using only text prompt as it often involves
arxiv.org
1. Introduction
Text prompt를 사용한 이미지 생성은 좋은 성능을 보였지만, text만으로 원하는 이미지를 만드는 것은 한계가 있었다. image prompt는 text prompt보다 더 많은 정보와 디테일을 담을 수 있기 때문에 image prompt가 많이 사용되었다. 본 논문은 이러한 아이디어에 따라 간단한 방식으로 Text-to-Image Diffusion model에 image prompt를 통해 생성 기능을 강화하고자 한다.
SD Image Variations 와 Stable unCLIP과 같은 이전 연구는 이미지 임베딩에서 직접 text-conditioned diffusion model을 fine-tuning하여 그 효과를 증명하였음. 그러나 이러한 방법의 단점은 다음과 같음.
- Text 를 사용하여 이미지를 생성하는 기존 기능을 제거하고, fine-tuning을 위해 큰 컴퓨팅 리소스가 필요하다.
- 이미지 prompt 기능을 동일한 Text to Image 모델에서 고안된 다른 custom 모델로 전송할 수 없기 때문에 fine-tuning된 모델은 재사용이 불가능하다.
- 새로운 모델은 ControlNet과 같은 기존 구조 제어 툴과 호환되지 않는 경우가 많아 downstream application에 문제를 야기한다.
이러한 문제에 따라 Prompt-free diffusion과 같은 모델은 텍스트 인코더를 이미지 인코더로 대체하는 것을 선택했는데 이 또한 단점이 있다.
- Image prompt만 지원되기 때문에 사용자는 Text, Image prompt를 동시에 사용할 수 없음
- Image encoder를 fine-tuning하는 것만으로 이미지 품질이 보장되지 않고, 일반화 문제가 발생할 수 있음
저자들은 기존 Text-to-Image 모델을 수정하지 않고 Image prompt를 사용할 수 있는지 궁금했다. ControlNet과 T2I-Adapter는 기존 text-to-image diffusion model에 추가 네트워크를 연결하여 이미지 생성을 가이드할 수 있음을 증명하였다(대부분의 논문이 추가 네트워크를 사용하였음). 이를 위해서 CLIP image encoder에서 추출된 image feature는 학습 가능한 Adapter를 사용하여 맵핑된 다음 text feature와 concat되고(기존 Text feature → Text feature + Adapter를 거친 image feature), 이 feature가 diffusion model의 Unet에 들어간다.
저자들은 이런 cross-attention module때문에 앞서 나온 문제들이 나온다고 주장한다. pre-trained diffusion model에서 cross-attention layer의 key와 value projection의 가중치는 text feature에 맞게 학습되기 때문에 image & text feature를 cross-attention layer에 병합하면 image feature를 text feature에 정렬하는 것에 불과하기 때문에 이미지의 세부적인 정보를 놓친다고 한다.
저자들은 이를 해결하기 위해 IP-Adapter라는 image prompt adapter를 제안하였다.
- Key word: Decoupled cross-attention mechanism
2. Related Work
최근 Text-to-Image Diffusion model은 기존 모델에 Adapter를 적용한 모델에 대한 이야기
3. Method
3.1. Prelimiaries
- 기본적인 Diffusion model의 이야기
- DDPM
- Training objective of diffusion model
- fast samplers
- DDIM
- PNDM
- DPM-solver
- conditional diffusion model
- classifier guidance(Diffusion model beat gans on image synthesis)
- classifier-free guidance
3.2. Image Prompt Adapter
Image Adapter는 pretrained text-to-image diffusion model을 사용해 image prompt가 포함된 이미지를 생성할 수 있도록 만들어졌다. 기존 대부분 방법론의 concat된 feature를 고정된 cross-attention layer에 공급해 diffusion model이 image prompt로부터 세밀한 특징을 포착하는 것을 방해한다. 이 문제를 해결하기 위해 저자들은 위 그림과 같이 image feature가 임베됭 되는 cross-attention layer를 추가하였다. IP-Adapter는 두 가지로 구성된다.
더보기
- image prompt로부터 image feature를 추출하는 image encoder
- image feature를 pretrained text-to-image diffusion model에 임베딩하기 위한 decoupled cross-attention 모듈
3.2.1. Image Encoder
대부분 방법론과 마찬가지로 pretrained CLIP image encoder 모델을 사용해서 image prompt에서 image feature를 추출했다. 학습 과정에서는 CLIP image encoder는 고정(freeze)하였음.
global image embedding을 효과적으로 분해하기 위해 linear layer와 Layer Normalization으로 구성된 trainable projection network를 사용해 이미지 임베딩을 길이 $N$(본 논문에서 $N=4$)의 feature 시퀀스로 porject한다. 이 때 이미지 feature의 차원은 pretrained diffusion model의 text feature와 동일하다.
3.2.2. Decoupled Cross-Attention
image feature는 decoupled cross-attention을 갖는 adapted module에 의해 pretrained Unet에 통합된다. 원본 Stable Diffusion 모델에서 CLIP text encoder의 text feature는 cross-attention layer에 공급되어 UNet에 연결된다. Query feature $Z$와 text feature $c_t$가 주어지면 cross-attention의 output $Z^\prime$은 아래와 같이 정의할 수 있다.
$$Z^\prime = \textrm{Attention} (Q, K, V) = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) V \\
\textrm{where} \; Q = ZW_q, \; K = c_t W_k, \; V = c_t W_v$$
저자들은 text feature와 image feature를 위한 cross attention layer가 분리된 decoupled cross-attention mechanism을 제안했다. cross-attention layer를 기존 UNet 모델의 cross-attention layer에 cross-attention layer를 추가하여 이미지 feature를 삽입한다. 이미지 feature $c_i$가 주어지면 새로운 cross-attention의 output은 $Z^{\prime \prime}$은 아래와 같이 계산된다.
$$Z^{\prime \prime} = \textrm{Attention} (Q, K^\prime, V^\prime) = \textrm{Softmax} (\frac{Q(K^\prime)^\top}{\sqrt{d}}) V^\prime \\
\textrm{where} \; Q = ZW_q, K^\prime = c_i W_k^\prime, V^\prime = c_i W_v^\prime$$
text cross-attention과 image cross-attention에 대해 동일한 query를 사용했다. 결과적으로 각 cross-attention layer에 두 개 파라미터 $W^\prime_k , W^\prime_v$만 추가하면 된다. 수렴 속도를 높이기 위해 $W^\prime_k , W^\prime_v$는 $W^_k , W_v$에서 초기화하였다. 그 다음, image cross-attention을 text cross-attention output에 더하였다. 최종적인 decoupled cross-attention의 공식은 아래와 같고, 기존 UNet을 얼려놓았기 때문에 $W^\prime_k , W^\prime_v$ 만 학습하면 된다.
$$Z^\textrm{new} = \textrm{Softmax} (\frac{QK^\top}{\sqrt{d}}) V + \textrm{Softmax} (\frac{Q(K^\prime)^\top}{\sqrt{d}}) V^\prime$$
3.2.3. Training and Inference
학습 과정에서는 pretrained diffusion model의 파라미터를 고정하고 IP-Adapter만 최적화하였고, 원본 Stable Diffusion과 동일한 목적 함수를 사용하여 image-text pair 데이터셋에 학습되었다.
$$L_\textrm{simple} = \mathbb{E}_{x_0, \epsilon, c_t, c_i, t} \| \epsilon - \epsilon_\theta (x_t, c_t, c_i, t) \|^2$$
inference 과정에서는 classifier-free guidance를 활성화하기 위해 학습 단계에서 image condition을 랜덤으로 삭제하였다.
$$\hat{\epsilon}_\theta (x_t, c_t, c_i, t) = w \epsilon_\theta (x_t, c_t, c_i, t) + (1-w) \epsilon_\theta (x_t, t)$$
image condition이 제거되면 CLIP 이미지 임베딩을 0으로 설정하였다. text cross-attention과 image cross-attention이 따로 분리되어있기 때문에 inference 과정에 image condition의 가중치를 조절할 수 있다. $\lambda = 0$이면 기존 text-to-image diffusion model이 된다.
$$Z^\textrm{new} = \textrm{Attention} (Q, K, V) + \lambda \cdot \textrm{Attention} (Q, K^\prime, V^\prime)$$
4. Experiments
4.1. Implementation Details
- Trianing
- LAION-2B, COYO-700 데이터셋
- SD v1.5
- OpenCLIP ViT-H/14 image encoder
- SD의 16개의 cross-attention layer에 새로운 image cross-attention layer를 추가
- 빠른 학습을 위한 DeepSpeed ZeRo-2 사용
- 8 V100 GPUs for 1M steps with batch size of 8 per GPU
- 512 x 512 resoultion으로 resize
- classifier-free guidance, image나 text 조건을 각각 제거하거나 둘 다 제거하기 위한 확률로 0.05를 사용
- Inference
- DDIM sampler with 50 steps
- guidance scale: 7.5
- only image prompt → $\lambda = 1.0$
4.2. Comparison with Existing Methods
3가지 타입의 방법론을 비교하였다.
- Training from scratch
- Fine-tuning from text-to-image model
- Adapters
COCO validation set에 따른 비교
- 각각 4개의 이미지를 생성
- CLIP-I: image prompt와 CLIP image embedding의 유사도
- CLIP-T: image prompt의 캡션과 생성된 이미지의 CLIP score
다른 종류와 스타일에 따른 이미지 결과 비교
image prompt와 추가 structual condition에 따른 결과
다른 structural condition에 따른 결과 비교
Image-to-Image & Inpainting 결과
Multimodal prompt에 따른 결과 비교
5. Conclusion
IP-Adapter를 제안하여 image prompt를 pretrained text-to-image diffusion model에 성공적으로 적용시켰다.
Image prompt를 pretrained T2I Diffusion model에 성공적으로 적용시킴. Decoupled cross-attention layer라는 방법을 사용했는데 $Z^\prime$이 더하는게 아닌 다른 방법은 어떤게 있을까...
'Study > Paper' 카테고리의 다른 글
| [논문리뷰] Mamba: Linear-Time Sequence Modeling with Selective State Spaces (0) | 2024.05.16 |
|---|---|
| [논문 리뷰] Generative Adversarial Networks (0) | 2024.04.03 |
| [논문리뷰] NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis (0) | 2023.06.06 |
| [논문리뷰] SinDiffusion: Learning a Diffusion Model from a Single Natural Image (0) | 2023.06.06 |
| Diffusion summary1 (0) | 2023.05.16 |