
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
In this paper, we present NUWA-Infinity, a generative model for infinite visual synthesis, which is defined as the task of generating arbitrarily-sized high-resolution images or long-duration videos. An autoregressive over autoregressive generation mechani
arxiv.org
1. Introduction
본 논문에서는 Infinite Visual Synthesis를 사용하여 임의의 크기의 고품질 이미지 또는 비디오를 생성하는 작업을 하며, NUWA-Infinity 를 통해 variable size generation task, computational cost의 challenge에 대해서 해결하고자함.
- NUWA-Infinity는 autoregressive over autoregressive 구조. global patch level autoregressive model이 patch간의 dependencies를 고려하고, token-level autoregressive model이 각 patch 간의 visual token을 고려함.
고정된 크기의 이미지만 생성할 수 있는 Diffusion based model과 다르게 autoregressive 방식은 자연스럽게 다른 level의 dependencies를 고려하고, 다양한 size의 생성이 가능함. 저자들은 생성중인 현재 patch에 대한 context로 이미 생성된 cache 관련 patch에 대한 NCP(Nearby Context Pool) 를 통해 patch level dependency modeling을 희생하지 않고, computing cost를 크게 줄임.
- 적절한 생성 순서를 결정하고 image outpainting에 매우 유용한 position ebeddings 을 학습하기 위한 ADC(Arbitary Direction controller)를 제안함
2. Related Work
Autoregressive Models
DALL-E
NUWA: First autoregressive visual synthesis pre-trained model to support image & video tasks
Diffusion Methods
DALL-E2는 input text로부터 image embedding을 autoregressive나 diffusion based model을 통해서 생성함.
Imagen
Infinite Visual Synthesis
GAN based models
서로 다른 패치에 대한 명시적인 종속성이 없기 때문에, inference 과정에서 서로 다른 패치를 병합하는데 일관성이 있는 결과가 안나올 수 있음. 이런 문제를 해결하기 위해 autoregressive을 통해 서로 다른 patch들을 sliding window에 적용해 매끄럽게 만듬. 최근에는 Mask-predict 방법을 sliding window 방식에 사용
3. Model
input $y$ → text or image
infinite visual synthesis는 이미지나 비디오를 생성 $x \in \mathbb{R}^{W \times H \times C \times F}$ . 이미지면 F = 1
NUWA-Infinity는 autoregressive over autoregressive model으로 아래 수식을 해결하고자함.
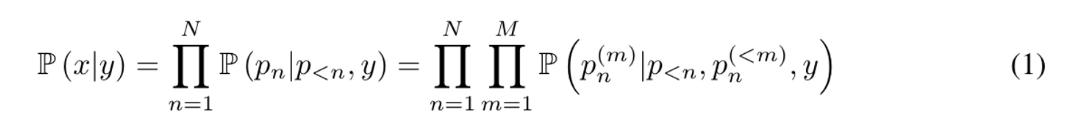
두번째항 $\Pi^{N}{n=1} \mathbb{P}(p_n|p{<n},y)$은 global autoregressive generation을 의미. $p_n$은 n 번째 생성되고 있는 patch를 의미함. N은 total patch의 개수. 세번째항은 local autoregressive generation procedure를 의미.
$p_n^{(m)}$은 $p_n$번째 만들어진 m번째 visual token. M은 전체 token수. 각 $p_n$은 pretrained VQGAN decoder를 통해 reconstruct 된다.
- input: visual token sequence
- final image or video: generated patches based on specific resolution
총 5가지 task에 대해서 적용함. Unconditional generation의 경우엔 input 없이 vision decoder로부터 생성됨. Image outpainting, Image Animation의 경우엔 input image가 vision decoder에 들어감. Text-to-image, Text-to-video의 경우 input text가 text encoder를 통해서 encoding되고, vision decoder를 통해서 video, image가 생성됨.
이미지, 동영상은 2,3차원이기 때문에 서로 다른 Visual synthesis tasks에 대해 서로 다른 패치 생성 순서를 고려하고 처리해야 함. 그래서 저자들은 적절한 patch generation orders를 계획하고, order-aware positional embeddings를 학습할 수 있는 Arbitrary Direction Controller(ADC)를 통해 이를 해결하고자함.
Visual tokens의 길이가 매우 크기 때문에 생성중인 현재 패치에 대한 context로 이미 생성된 cache 관련 패치를 cache하기 위해 Nearly Context Pool(NCP)를 제안해 패치 수준 종속성 모델링을 희생하지않고, computing cost를 절감할 수 있음
저자들은 NUWA-Infinity를 high-quality image-text pair를 크롤링해서 학습시킴
3.1 Arbitrary Direction Controller
Split: splits video/image and decides the patch generation order for training and inference procedures
이미지, 비디오를 입력으로 받아 ordered patch sequences를 반환
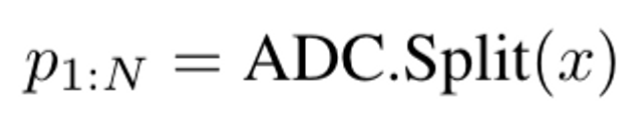
Splits 과정을 보여주는 figure $\downarrow$
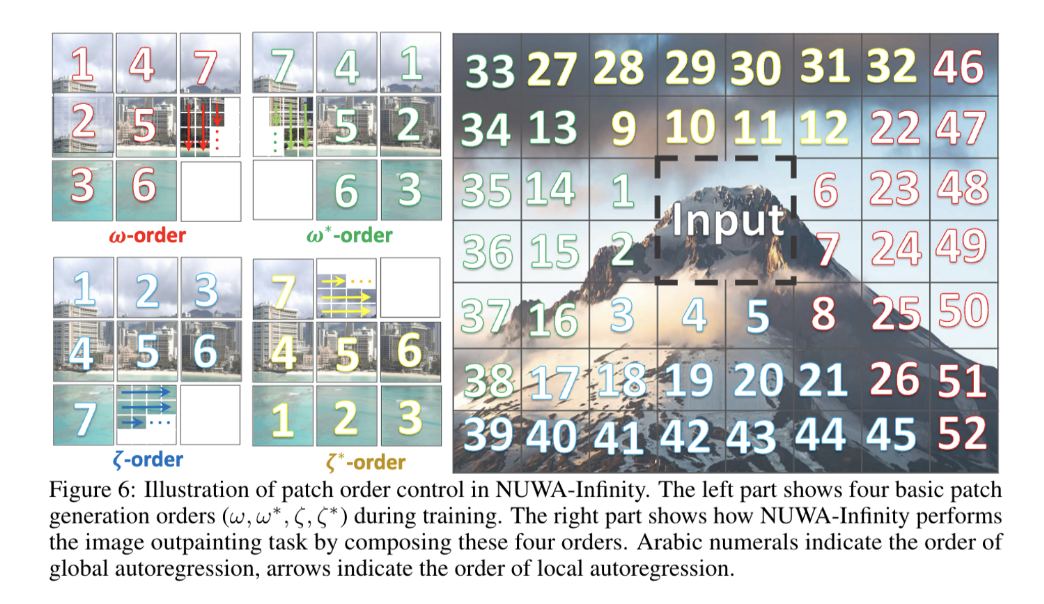
training과정에서 split이 어떻게 작동하는지(좌)
- 4가지 generation orders를 제안*: reversed writing order
image outpainting의 inference 과정에서 split이 어떻게 작동하는지
Emb
$p_n$의 context로 이미 생성되고 선택된 $p_n$ 및 $c_n$의 패치에 positional embeddings을 할당
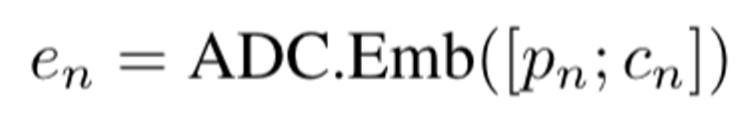
dynamic postional embeddings을 ADC에 사용
18 dynamic embeddings
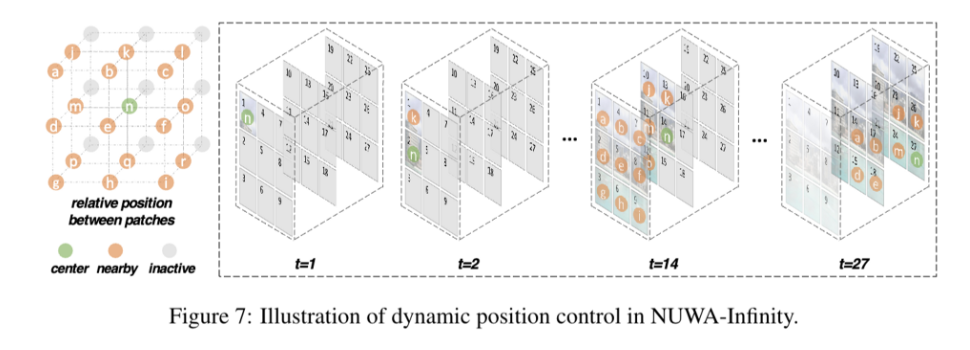
- center patch = $n$ 으로 label(초록색)
- 이전에 생성된 $n$ 으로부터 생성된 패치들은 다르게 label(주황색)
- → $18 \times d$ 의 embedding matrix가 생성
3.2 Nearby Context Pool(NCP)
기존 idea들은 인접한 패치를 context로 활용하는 것인데, 그러면 멀리있는 내용을 참고하지 못해 long-term memory에 대한 손실과 생성된 이미지, 비디오의 global consistency가 망가질 수 있음.
위 문제를 보완하기 위해 3가지 함수의 NCP를 제안함
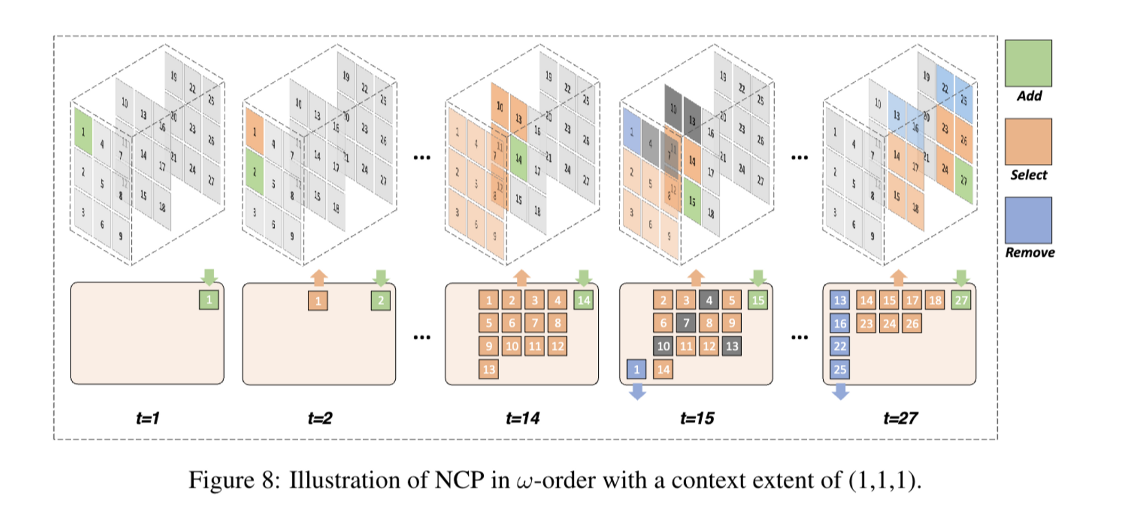
Add
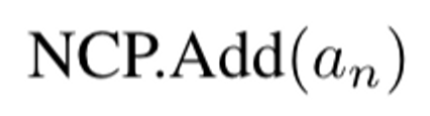
이미 생성된 $p_n$의 cache $a_n$를 NCP에 넣음. $p_n$의 cache $a_n$: resulting multi-layer hidden states from the generation of $p_n$
Select

selects the context $c_n$ for the patch $p_n$ to be generated. $p_n$의 context $c_n$은 미리 정의된 범위$(e^w, e^h, e^f)$ 내에서 이미 생성된 패치의 cache로 정의되며 height, width, frame을 나타냄.
Remove
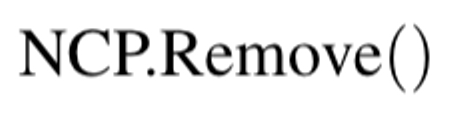
미래 패치에 영향을 주지 않는 cache를 제거
3.3 Training and Inference Strategy
3.3.1. Training Strategy
- input-output pair: $<y, x \in \mathbb{R}^{W \times H \times C \times F}>$
- 먼저 visual data x를 patches로 쪼갬. 랜덤으로 patch generation order를 선택(4가지)
- pretrained VQGAN encoder가 x의 모든 이미지를 visual tokens $[p_1^{(1)}, ..., p_1^{(M)},...,p_N^{(N)},...,p_N^{(M)}]$으로 변환하고, 각 패치들은 해당하는 visual tokens로 표현됨.
- y는 encodding된 text
저자들은 NUWA-Infinity를 ordered patch sequence $r$에 따라 학습시킴. 패치를 뽑으면, NCP에 따라 context $c_n$을 추출함.
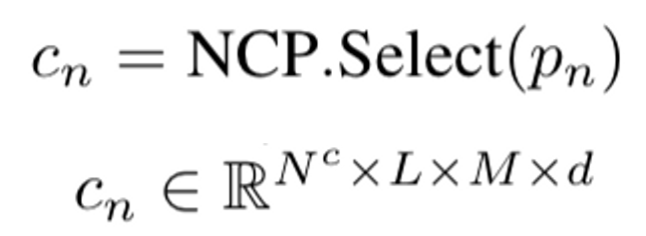
- $N^c$: $q$안에 패치 개수
- $L$: vision decoder의 layer 개수
- $M$: 각 context patch의 vision token 개수
- $d$: vision token embedding dimension
$p_n$과 $c_n$의 positional embeddings
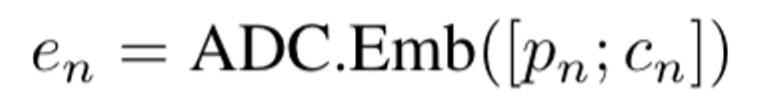
$L$개 layer의 vision decoder가 $p_n$과 $c_n$을 input으로 받음
1st layer: $p_n$, 1st hidden states $c_n^{(1)} \in \mathbb{R}^{N^c \times M \times d}$ 모든 패치 $c_n$이 self-attention module에 태워짐.

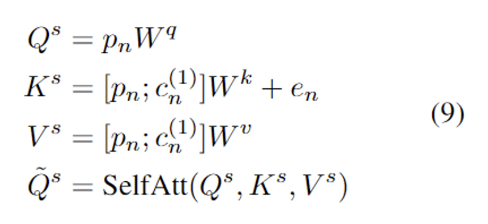
Text-to-Image task 에서는, $\tilde Q^s, y'$를 cross attention module에 아래 수식과 같이 태움.
text input이 없는 task에서는 $\tilde Q^s$, text input이 있는 task에서는 $\tilde Q^c$가 feed-forward network에 넣어지고, 1st layer $\hat p_n^{(1)} \in \mathbb{R} ^{M \times d}$의 output이 얻어짐.
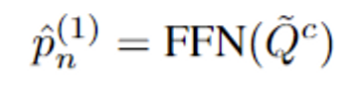
$L$개 layer가 쌓이면, 각 layer에서 $\hat p_n ^{(1)}, ..., \hat p_n^{(L-1)} \in \mathbb{R}^{M \times d}$을 얻을 수 있음. $L-1$ layer outputs과 $p_n$이 concat되어서 $$$p_n$번째 패치의 $L$ layer cache를 얻음.
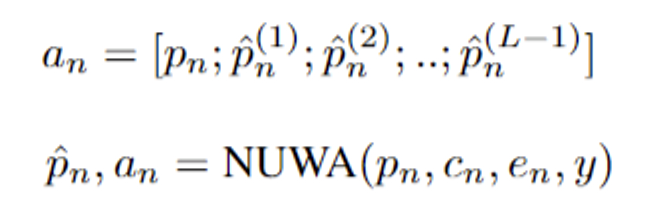
$\hat p_n = \hat p_n^{(L)}$은 output embeddings. NCP는 $p_n$의 cache를 모아서 다음 패치를 예측하는 것을 돕고, 필요없는 패치를 제거하는데 사용된다.

마지막으로 cross-entropy loss가 model optimize에 사용
3.3.2. Inference Startegy

Image Outpainting, Image Animation, Text-to-Image, Text-to-Video task에는 두 가지 특별함이 있음 → Image Condition Pre-caching and Pixel-Guided VQGAN
- Image Condition Pre-caching
- Image Outpainting, Image Animation에서 input → image condition $h$, output: spatial extended image or a temporal extended video.
- VQGAN encoder가 $h$를 인코딩해서 각 visual token에 해당하는 patches의 list로 만들어짐.
- $K$: conditional patches → 이 패치들과 visual tokens이 vision decoder(attention)에 태워짐 → 다음 frame이나 이미지를 만들어냄
- Pixel-Guided VQGAN
- Image Animation, Text-to-Video → output = videos
- VQVAE: trained only images → frame by frame으로 만들어내면 inconsistency!
- Pixel-Guided VQGAN을 제안
- 2개의 연속 frames을 training에 사용하고, $n-1$의 pixel-level 정보를 decoder frame에 더함
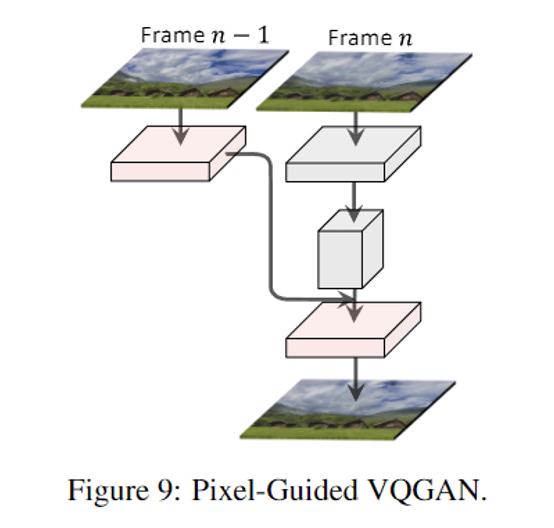
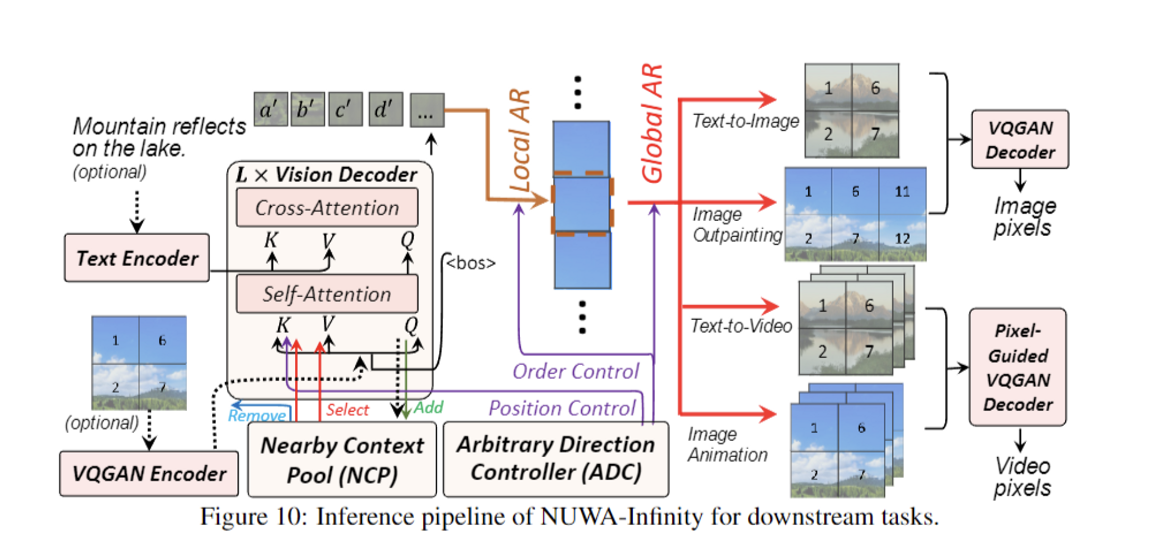
4. Experiments
4.1 Datasets
- RQF: Riverside of Qingming Festival
- LHQC: Landscape High Quality with Captions
- LHQ-V: Landscape High Quality for Videos
- PeppaPig
4.2 Implementation Details
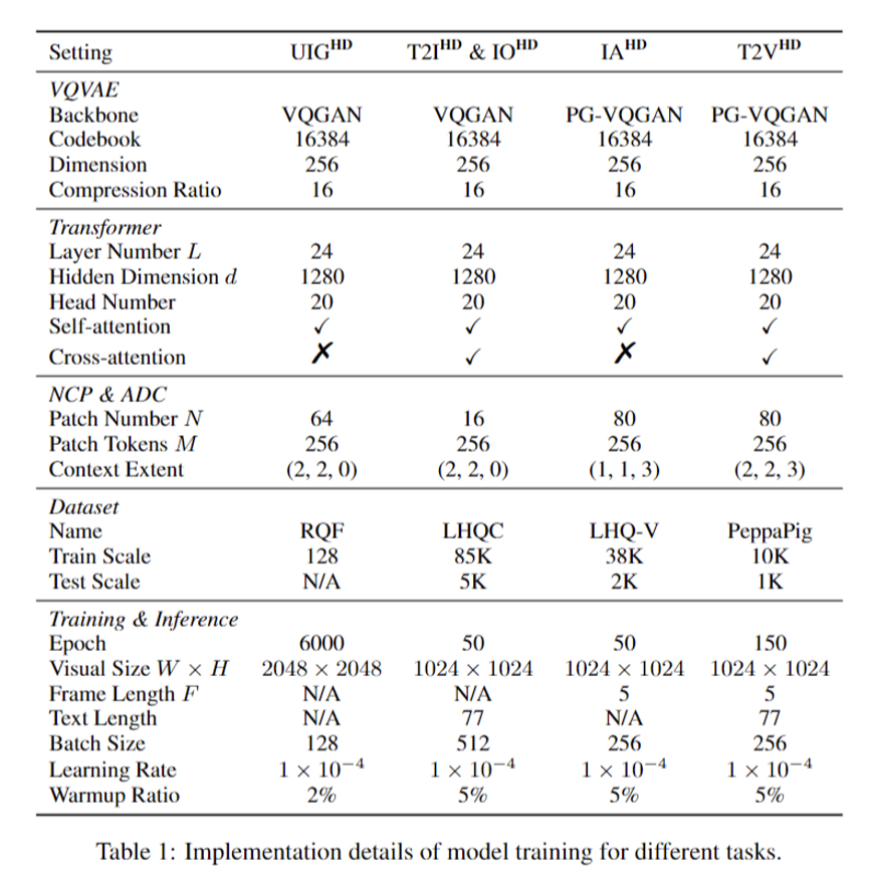
- cropped into 1024 x 1024
- x 5fps
- VQGAN model로 encoded with compression ratio of 16
- Adam optimizer
- learning rate: 10^-4
- batch size: 256
4.3 Metrics
- FID/Block-FID
- IS
- FVD
- CLIP-SIM(CLIP Similarity Score)
4.4 Main Results
Image Outpainting
- 저자들은 NUWA-Infinity를 image outpainting을 위해 학습시키지 않음
- → Text-to-Image에 학습시킨 모델을 사용함.
- 4개의 방향을 정해줌. ($\Rightarrow, \Leftarrow, \Downarrow, \Uparrow$)
- 그냥 반 자르고 정량적인 평가를 한거임!!

'Study > Paper' 카테고리의 다른 글
| [논문 리뷰] Generative Adversarial Networks (0) | 2024.04.03 |
|---|---|
| [논문리뷰] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (0) | 2024.03.21 |
| [논문리뷰] SinDiffusion: Learning a Diffusion Model from a Single Natural Image (0) | 2023.06.06 |
| Diffusion summary1 (0) | 2023.05.16 |
| [논문 리뷰] High-Resolution Image Synthesis with Latent Diffusion Models(Stable Diffusion) (0) | 2023.05.15 |
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
In this paper, we present NUWA-Infinity, a generative model for infinite visual synthesis, which is defined as the task of generating arbitrarily-sized high-resolution images or long-duration videos. An autoregressive over autoregressive generation mechani
arxiv.org
1. Introduction
본 논문에서는 Infinite Visual Synthesis를 사용하여 임의의 크기의 고품질 이미지 또는 비디오를 생성하는 작업을 하며, NUWA-Infinity 를 통해 variable size generation task, computational cost의 challenge에 대해서 해결하고자함.
- NUWA-Infinity는 autoregressive over autoregressive 구조. global patch level autoregressive model이 patch간의 dependencies를 고려하고, token-level autoregressive model이 각 patch 간의 visual token을 고려함.
고정된 크기의 이미지만 생성할 수 있는 Diffusion based model과 다르게 autoregressive 방식은 자연스럽게 다른 level의 dependencies를 고려하고, 다양한 size의 생성이 가능함. 저자들은 생성중인 현재 patch에 대한 context로 이미 생성된 cache 관련 patch에 대한 NCP(Nearby Context Pool) 를 통해 patch level dependency modeling을 희생하지 않고, computing cost를 크게 줄임.
- 적절한 생성 순서를 결정하고 image outpainting에 매우 유용한 position ebeddings 을 학습하기 위한 ADC(Arbitary Direction controller)를 제안함
2. Related Work
Autoregressive Models
DALL-E
NUWA: First autoregressive visual synthesis pre-trained model to support image & video tasks
Diffusion Methods
DALL-E2는 input text로부터 image embedding을 autoregressive나 diffusion based model을 통해서 생성함.
Imagen
Infinite Visual Synthesis
GAN based models
서로 다른 패치에 대한 명시적인 종속성이 없기 때문에, inference 과정에서 서로 다른 패치를 병합하는데 일관성이 있는 결과가 안나올 수 있음. 이런 문제를 해결하기 위해 autoregressive을 통해 서로 다른 patch들을 sliding window에 적용해 매끄럽게 만듬. 최근에는 Mask-predict 방법을 sliding window 방식에 사용
3. Model
input $y$ → text or image
infinite visual synthesis는 이미지나 비디오를 생성 $x \in \mathbb{R}^{W \times H \times C \times F}$ . 이미지면 F = 1
NUWA-Infinity는 autoregressive over autoregressive model으로 아래 수식을 해결하고자함.
두번째항 $\Pi^{N}{n=1} \mathbb{P}(p_n|p{<n},y)$은 global autoregressive generation을 의미. $p_n$은 n 번째 생성되고 있는 patch를 의미함. N은 total patch의 개수. 세번째항은 local autoregressive generation procedure를 의미.
$p_n^{(m)}$은 $p_n$번째 만들어진 m번째 visual token. M은 전체 token수. 각 $p_n$은 pretrained VQGAN decoder를 통해 reconstruct 된다.
- input: visual token sequence
- final image or video: generated patches based on specific resolution
총 5가지 task에 대해서 적용함. Unconditional generation의 경우엔 input 없이 vision decoder로부터 생성됨. Image outpainting, Image Animation의 경우엔 input image가 vision decoder에 들어감. Text-to-image, Text-to-video의 경우 input text가 text encoder를 통해서 encoding되고, vision decoder를 통해서 video, image가 생성됨.
이미지, 동영상은 2,3차원이기 때문에 서로 다른 Visual synthesis tasks에 대해 서로 다른 패치 생성 순서를 고려하고 처리해야 함. 그래서 저자들은 적절한 patch generation orders를 계획하고, order-aware positional embeddings를 학습할 수 있는 Arbitrary Direction Controller(ADC)를 통해 이를 해결하고자함.
Visual tokens의 길이가 매우 크기 때문에 생성중인 현재 패치에 대한 context로 이미 생성된 cache 관련 패치를 cache하기 위해 Nearly Context Pool(NCP)를 제안해 패치 수준 종속성 모델링을 희생하지않고, computing cost를 절감할 수 있음
저자들은 NUWA-Infinity를 high-quality image-text pair를 크롤링해서 학습시킴
3.1 Arbitrary Direction Controller
Split: splits video/image and decides the patch generation order for training and inference procedures
이미지, 비디오를 입력으로 받아 ordered patch sequences를 반환
Splits 과정을 보여주는 figure $\downarrow$
training과정에서 split이 어떻게 작동하는지(좌)
- 4가지 generation orders를 제안*: reversed writing order
image outpainting의 inference 과정에서 split이 어떻게 작동하는지
Emb
$p_n$의 context로 이미 생성되고 선택된 $p_n$ 및 $c_n$의 패치에 positional embeddings을 할당
dynamic postional embeddings을 ADC에 사용
18 dynamic embeddings
- center patch = $n$ 으로 label(초록색)
- 이전에 생성된 $n$ 으로부터 생성된 패치들은 다르게 label(주황색)
- → $18 \times d$ 의 embedding matrix가 생성
3.2 Nearby Context Pool(NCP)
기존 idea들은 인접한 패치를 context로 활용하는 것인데, 그러면 멀리있는 내용을 참고하지 못해 long-term memory에 대한 손실과 생성된 이미지, 비디오의 global consistency가 망가질 수 있음.
위 문제를 보완하기 위해 3가지 함수의 NCP를 제안함
Add
이미 생성된 $p_n$의 cache $a_n$를 NCP에 넣음. $p_n$의 cache $a_n$: resulting multi-layer hidden states from the generation of $p_n$
Select
selects the context $c_n$ for the patch $p_n$ to be generated. $p_n$의 context $c_n$은 미리 정의된 범위$(e^w, e^h, e^f)$ 내에서 이미 생성된 패치의 cache로 정의되며 height, width, frame을 나타냄.
Remove
미래 패치에 영향을 주지 않는 cache를 제거
3.3 Training and Inference Strategy
3.3.1. Training Strategy
- input-output pair: $<y, x \in \mathbb{R}^{W \times H \times C \times F}>$
- 먼저 visual data x를 patches로 쪼갬. 랜덤으로 patch generation order를 선택(4가지)
- pretrained VQGAN encoder가 x의 모든 이미지를 visual tokens $[p_1^{(1)}, ..., p_1^{(M)},...,p_N^{(N)},...,p_N^{(M)}]$으로 변환하고, 각 패치들은 해당하는 visual tokens로 표현됨.
- y는 encodding된 text
저자들은 NUWA-Infinity를 ordered patch sequence $r$에 따라 학습시킴. 패치를 뽑으면, NCP에 따라 context $c_n$을 추출함.
- $N^c$: $q$안에 패치 개수
- $L$: vision decoder의 layer 개수
- $M$: 각 context patch의 vision token 개수
- $d$: vision token embedding dimension
$p_n$과 $c_n$의 positional embeddings
$L$개 layer의 vision decoder가 $p_n$과 $c_n$을 input으로 받음
1st layer: $p_n$, 1st hidden states $c_n^{(1)} \in \mathbb{R}^{N^c \times M \times d}$ 모든 패치 $c_n$이 self-attention module에 태워짐.
Text-to-Image task 에서는, $\tilde Q^s, y'$를 cross attention module에 아래 수식과 같이 태움.
text input이 없는 task에서는 $\tilde Q^s$, text input이 있는 task에서는 $\tilde Q^c$가 feed-forward network에 넣어지고, 1st layer $\hat p_n^{(1)} \in \mathbb{R} ^{M \times d}$의 output이 얻어짐.
$L$개 layer가 쌓이면, 각 layer에서 $\hat p_n ^{(1)}, ..., \hat p_n^{(L-1)} \in \mathbb{R}^{M \times d}$을 얻을 수 있음. $L-1$ layer outputs과 $p_n$이 concat되어서 $$$p_n$번째 패치의 $L$ layer cache를 얻음.
$\hat p_n = \hat p_n^{(L)}$은 output embeddings. NCP는 $p_n$의 cache를 모아서 다음 패치를 예측하는 것을 돕고, 필요없는 패치를 제거하는데 사용된다.
마지막으로 cross-entropy loss가 model optimize에 사용
3.3.2. Inference Startegy
Image Outpainting, Image Animation, Text-to-Image, Text-to-Video task에는 두 가지 특별함이 있음 → Image Condition Pre-caching and Pixel-Guided VQGAN
- Image Condition Pre-caching
- Image Outpainting, Image Animation에서 input → image condition $h$, output: spatial extended image or a temporal extended video.
- VQGAN encoder가 $h$를 인코딩해서 각 visual token에 해당하는 patches의 list로 만들어짐.
- $K$: conditional patches → 이 패치들과 visual tokens이 vision decoder(attention)에 태워짐 → 다음 frame이나 이미지를 만들어냄
- Pixel-Guided VQGAN
- Image Animation, Text-to-Video → output = videos
- VQVAE: trained only images → frame by frame으로 만들어내면 inconsistency!
- Pixel-Guided VQGAN을 제안
- 2개의 연속 frames을 training에 사용하고, $n-1$의 pixel-level 정보를 decoder frame에 더함
4. Experiments
4.1 Datasets
- RQF: Riverside of Qingming Festival
- LHQC: Landscape High Quality with Captions
- LHQ-V: Landscape High Quality for Videos
- PeppaPig
4.2 Implementation Details
- cropped into 1024 x 1024
- x 5fps
- VQGAN model로 encoded with compression ratio of 16
- Adam optimizer
- learning rate: 10^-4
- batch size: 256
4.3 Metrics
- FID/Block-FID
- IS
- FVD
- CLIP-SIM(CLIP Similarity Score)
4.4 Main Results
Image Outpainting
- 저자들은 NUWA-Infinity를 image outpainting을 위해 학습시키지 않음
- → Text-to-Image에 학습시킨 모델을 사용함.
- 4개의 방향을 정해줌. ($\Rightarrow, \Leftarrow, \Downarrow, \Uparrow$)
- 그냥 반 자르고 정량적인 평가를 한거임!!
'Study > Paper' 카테고리의 다른 글
| [논문 리뷰] Generative Adversarial Networks (0) | 2024.04.03 |
|---|---|
| [논문리뷰] IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (0) | 2024.03.21 |
| [논문리뷰] SinDiffusion: Learning a Diffusion Model from a Single Natural Image (0) | 2023.06.06 |
| Diffusion summary1 (0) | 2023.05.16 |
| [논문 리뷰] High-Resolution Image Synthesis with Latent Diffusion Models(Stable Diffusion) (0) | 2023.05.15 |